
Codificadores automáticos dispersos
Tiempo de lectura: 4 minutos
Los codificadores automáticos dispersos nos pueden ayudar a entender cómo dar sentido a la actividad neuronal de las IAs. ¿Entenderemos cómo funcionan las IAs?
El problema
Actualmente estamos en busca de la AGI (Inteligencia artificial general, de uso multidisciplinar) y estamos haciendo progresos, ante los cuales, algunos lo ven como inminente. Pero el mayor problema para los investigadores es que no entendemos cómo darle sentido a la actividad neuronal dentro de los modelos de lenguaje. O sea, no sabemos cómo funciona.
Las redes neuronales no se diseñan directamente, se diseña la arquitectura, pero no establecemos el contenido; en cambio, sí que diseñamos los algoritmos que los entrenan y, en ese proceso, les dan el contenido.
Las redes resultantes no se comprenden bien y no se pueden descomponer fácilmente en partes identificables. Por lo tanto, no podemos razonar sobre la seguridad de la IA de la misma manera que razonamos sobre algo como la seguridad de los automóviles, que diseñamos y entendemos pieza a pieza.
Da miedo, ¿eh?
Codificadores automáticos
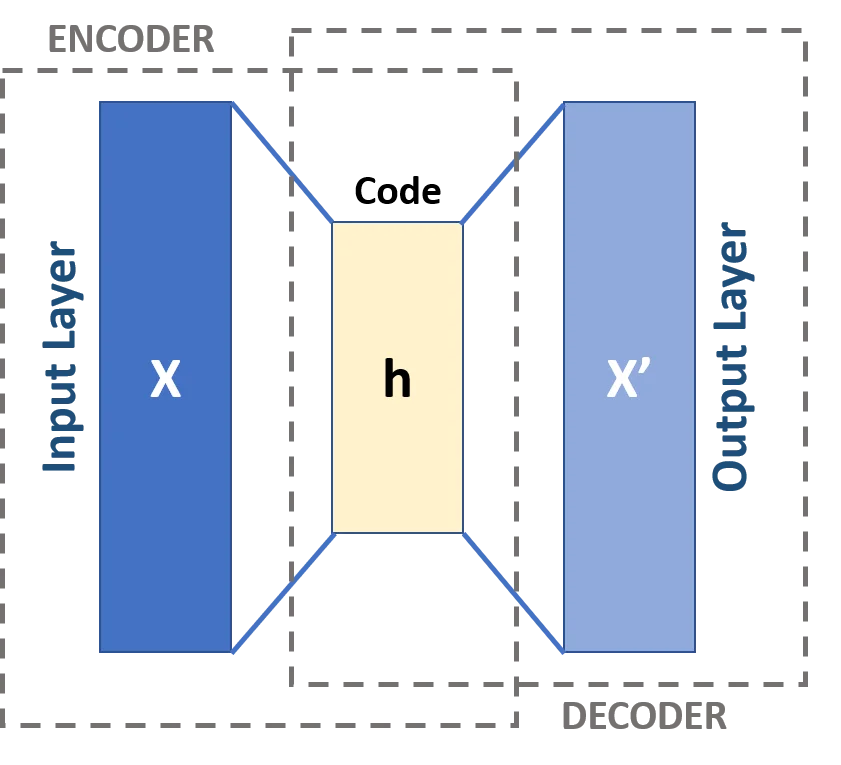
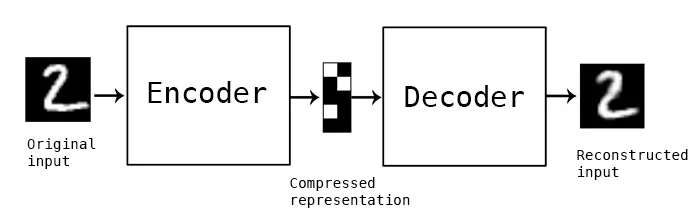
Los codificadores automáticos son un tipo de red neuronal que tienen como objetivo aprender representaciones eficientes de datos de entrada codificándolos en los nodos de la red, con menor número de dimensiones, y luego reconstruyéndolos para obtener los datos originales. Es como una abstracción o compresión de los datos.
Constan de dos partes simétricas: el codificador, que comprime los datos de entrada en una representación latente, y el decodificador, que reconstruye los datos originales a partir de esta representación latente.
La reconstrucción de los datos debería ser exacta al original, pero no es totalmente así, y si minimizamos la diferencia entre los datos de entrada y los reconstruidos, los codificadores automáticos pueden extraer características significativas que pueden usarse para diversas tareas. Más adelante enumero algunas aplicaciones.
Esto se puede representar así: dado un conjunto de datos x, codificamos en h
h = E(x)Y recuperamos con el decodificador:
x' = D(h) = D(E(x))El objetivo es minimizar la pérdida de reconstrucción, la función L(x, y), que mide la diferencia entre la entrada original y la salida reconstruida. Es la función de pérdida:
L(x, x') = (1/n) ∑ (xᵢ – x'ᵢ)²A la que se le añade la regularización para evitar el overfitting:
Lf = L(x, x') + regularizaciónLos codificadores automáticos tienen varias aplicaciones:
- Reducción de dimensionalidad. Al reducir la dimensionalidad de los datos de entrada, los codificadores automáticos pueden simplificar conjuntos de datos complejos y al mismo tiempo preservar información importante.
- Extracción de características. La representación latente aprendida por el codificador se puede utilizar para extraer características útiles para tareas como la clasificación de imágenes o identificar personas.
- Detección de anomalías. Los codificadores automáticos pueden entrenarse para reconstruir patrones de datos normales, haciéndolos eficaces a la hora de identificar anomalías que se desvían de estos patrones, como encontrar un tumor en una tomografía.
- Generación de imágenes. Algunas variantes pueden generar nuevas muestras de datos similares a los datos de entrenamiento para obtener imágenes a petición o para entrenar otros modelos.
La posible solución
Los codificadores automáticos dispersos (SAE por sus siglas en inglés) funcionan de la misma forma, pero incorporan una penalización en la función de pérdida. Esta penalización provoca que la mayoría de nodos ocultos no se activen, de manera que sólo un pequeño subconjunto de unidades esté activo en un momento dado.
La función de pérdida para entrenar un codificador automático disperso incluye la pérdida de reconstrucción y la penalización:
Lt = L( x, y ) +regularización + λ penalizaciónDe forma intuitiva podemos explicarlo con un ejemplo: si un hombre afirma ser un experto en matemáticas, informática, psicología y música clásica, en general aprende conocimientos bastante superficiales en cada una de las materias. Sin embargo, si solo es experto en matemáticas, seguramente nos dará información más precisa, útil y detallada. Y ocurre lo mismo con los codificadores automáticos: activar menos nodos manteniendo su rendimiento garantizaría que el codificador automático aprenda representaciones latentes en lugar de información redundante y confusa de los datos de entrada.
Resultados esperados
La idea es descomponer la activación en características. Y utilizar el mínimo de activaciones para tenerlas claras.
Existe evidencia empírica significativa que sugiere que las redes neuronales tienen direcciones lineales interpretables en el espacio de activación.
Si las direcciones lineales son interpretables, es natural pensar que existe un conjunto básico de direcciones significativas a partir del cual se pueden crear direcciones más complejas.
Estas direcciones son las llamadas características, en las que que nos gustaría descomponer los modelos.
Casos prácticos, Claude 3
El equipo de Anthropic entrenó varios SAE sobre la capa media de su modelo Claude 3 y se escogieron diferentes características detectadas con los SAE. Los resultados de los ejemplos se pueden ver en detalle aquí. Una de las características extraídas era "El puente Golden Gate". Sus mayores activaciones son esencialmente todas referencias al puente, y las activaciones más débiles también incluyen atracciones turísticas relacionadas, puentes similares y otros monumentos.
Este resumen es impresionante:

En la imagen se puede ver el mapa de características que se han extraído del Claude 3. Hay millones de características en el mapa, con su proximidad a otras.
Cada característica se identifica com los activadores, que nos permiten identificar la característica, pero son muy abstractas y generalizadas, demás no dependen del idioma.
Lo mejor es que después se pueden utilizar como clasificadores para controlar el comportamiento de los modelos. Es decir, que realmente se están extrayendo características que corresponden a la interpretación.
En la característica del puente Golden Gate, se pudo hacer que tuviera un peso muy importante en la activación y lo que se consiguió fue que la IA pensava que ERA el Golden Gate. Así todas sus respuestas estaban condicionadas por lo "que puede hacer un puente" como el Golden Gate. Es decir, si le preguntas, por ejemplo, que te escriba una historia te responderá que los puentes no pueden escribir historias aunque conocen muchas relacionadas con las personas que lo cruzan.
Conclusiones
En resumen, este es un camino para poder entender el funcionamiento de lo grandes modelos y, sobre todo, poder dirigirlos y focalizarlos a través de las características. Este es un punto muy interesante e importante para garantizar que creamos modelos de IA que respondan con garantías a las cuestiones que se les plantean. Y podríamos llegar a entender cómo "piensan".
- Claude 3 Sonnet
https://transformer-circuits.pub - Decompose GPT
https://openai.com - Sparse Autoencoders
https://www.unite.ai - Interpretable Features
https://arxiv.org - Claude 3 sample
https://transformer-circuits.pub