
Aprender a razonar
Tiempo de lectura: 3 minutos
Un paper de 2022 presenta la metodología Self-Taught Reasoner (STAR): un enfoque para aumentar las capacidades de razonamiento de grandes modelos de lenguaje (LLM) mediante la generación de razonamiento paso a paso.
El camino a la AGI
Hemos visto que los proyectos secretos para conseguir crear una AGI ya han definido unos grados de progreso para cuantificar el avance. Y también para ir más allá y crear una super-inteligencia, aunque todavía estemos en el nivel 1, como se indicaba.
Pero, ¿cómo se pretende conseguir este desarrollo? El enfoque no es aumentar la potencia de los data centers para crear redes mayores sino en crear nuevas técnicas de aprendizaje, razonamiento, fine tunning, etc. La tecnología descrita en el paper tiene como objetivo cerrar significativamente la brecha entre la cognición humana y la máquina.
En resumen
El paper se resume así:
Proponemos una técnica para aprovechar de forma iterativa una pequeña cantidad de razonamiento y un gran conjunto de datos sin razonar, para impulsar la capacidad de realizar razonamientos sucesivamente más complejos. Esta técnica, el "razonador autodidacta" (STaR), se basa en un ciclo simple: generar razonamientos para responder muchas preguntas, activado por algunos ejemplos de razonamiento; si las respuestas generadas son incorrectas, intenta nuevamente generar una justificación dada la respuesta correcta; afinar todos los razonamientos que finalmente produjeron respuestas correctas; repetir.
Mostramos que STaR mejora significativamente el rendimiento en múltiples conjuntos de datos en comparación con un modelo ajustado para predecir directamente las respuestas finales, por lo tanto, STaR permite que un modelo se mejore a sí mismo aprendiendo de su propio razonamiento generado.
Explicación
En el siguiente diagrama se refleja el proceso de autoaprendizaje que da nombre al algoritmo con la siguiente pregunta de ejemplo: ¿Qué se puede usar para llevar a un perro pequeño?
Respuestas:
- Piscina
- Cesta
- Espectáculo de perros
- Patio
- La casa propia
"la respuesta debe ser algo que se pueda usar para llevar a un perro pequeño. Las castas están diseñados para contener cosas. por lo tanto, la respuesta es una cesta."
Stanford University.
Google Research
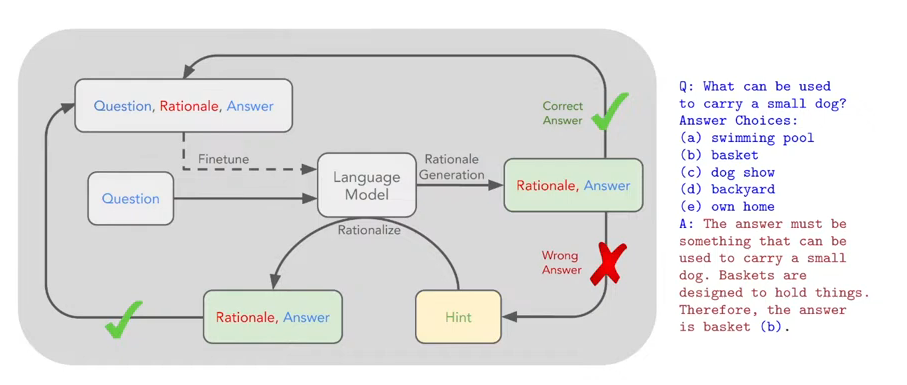
El tema es cómo ha podido razonar que esta es la única respuesta correcta. podríamos pensar que el modelo realmente razona, como así nos da a entender, pero es debido a un post aprendizaje.
La explicación intuitiva del diagrama es esta: el modelo procesa la pregunta y se le pide que razone la respuesta. En rojo se marca el razonamiento y en azul la respuesta.
Para cada problema que el modelo no responde correctamente, se genera una nueva justificación proporcionando al modelo la respuesta correcta. Esto permite que el modelo razone hacia atrás: dada la respuesta correcta, el modelo puede generar más fácilmente una justificación útil. Luego, estos razonamientos se recopilan como parte de los datos de entrenamiento, lo que a menudo mejora la precisión general. A esto lo llaman rationalization.
En el método, repetimos el siguiente proceso: en cada iteración, primero se construye un conjunto de datos de ajuste intentando resolver el conjunto de datos utilizando la capacidad de generación de razonamientos del modelo actual; luego, aumentar este conjunto de datos mediante la rationalization, justificando respuestas reales a los problemas que el modelo no logró resolver; finalmente, ajustar el modelo en el conjunto de datos combinado.
Stanford University.
Google Research

Q-STaR
Una generalización de STaR es Quiet-STaR, que pretende llevarlo un paso más allá. Se trata de que los modelos aprenden a generar razonamientos en cada token, en paralelo a la predicción de texto, para explicar textos futuros, mejorando sus predicciones. Durante el proceso de generación de la respuesta el modelo va descartando los tokens que no quedan revalorizados por los razonamientos.
Esto tiene como reflejo para el usuario que el modelo tarde más en responder, como si pensara lo que va a decir, y generando una respuesta más exacta.
Ligando cabos
Como curiosidad, podemos entender que el nombre de la tecnología es un acrónimo que significa estrella, o asterisco. Justamente el asterisco que aparecía en el proyecto de OpenAI, Q*, que vendría a ser Quiet-STaR. Además, el renovado proyecto secreto de OpenAI se llama Strawberry, cuya fonética se asemeja, y empieza por las mismas letras.
Conclusión
Toda la información del razonamiento se obtiene de los datos de entrenamiento del modelo, la única intervención externa es decidir si el razonamiento es correcto o no. Este algoritmo es la base para que los modelos puedan resolver problemas cada vez más difíciles.
Quiet-STaR representa un enfoque pionero en la evolución continua de los modelos lingüísticos. Al enseñar a los modelos a pensar antes de hablar, esta investigación arroja luz sobre el desarrollo de modelos que puedan razonar, interpretar y generar texto con matices y profundidad que reflejen los procesos de pensamiento humanos.
- STaR
https://openreview.net - Quiet-STaR
https://arxiv.org - Código
https://github.com