
¿Nos vamos a quedar sin datos?
Tiempo de lectura: 2 minutos
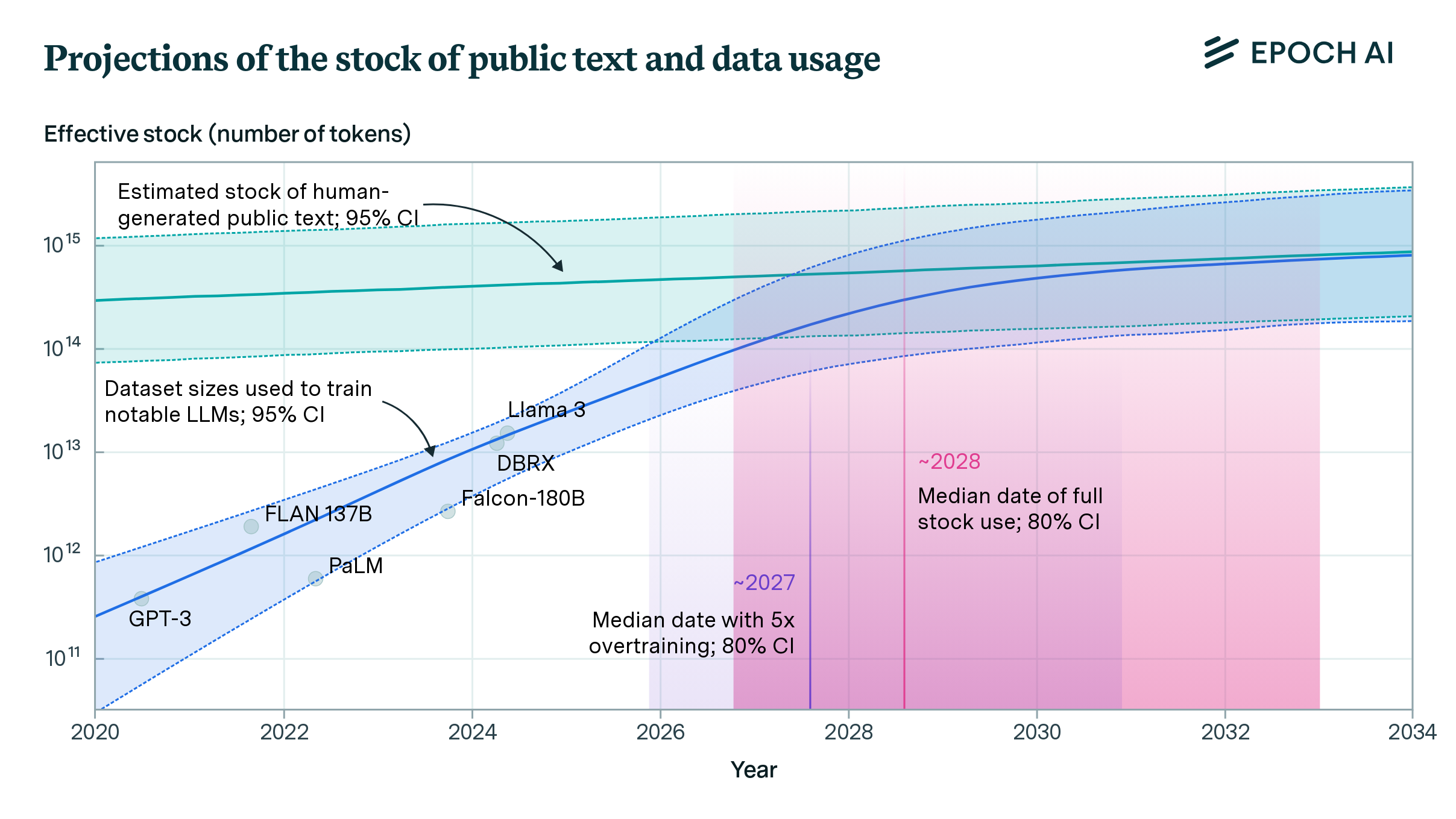
Se estima que el stock de texto público generado por humanos es de alrededor de 300 billones de tokens. Los modelos lingüísticos utilizarán todo este stock entre 2026 y 2032
Entrenamiento
Los grandes modelos de IA requieren de dos grandes recursos: un enorme poder de cálculo, o de computación (que tiene como consecuencia un gran consumo energético), y una gran cantidad de datos para entrenar los modelos.
Desde 2010 el crecimiento de computación usado para entrenar las IAs ha crecido a un ritmo en que se cuadruplica por cuatro. Un estudio publicado en junio de este año por varios autores, Pablo Villalobos, Anson Ho, Jaime Sevilla, Tamay Besiroglu, Lennart Haim y Marius Hobbhahn, pone de manifiesto que el consumo de datos para entrenamiento de IAs está llegando al límite.
Si la tendencia continúa, los modelos lingüísticos utilizarán plenamente este stock entre 2026 y 2032, o incluso antes si se les somete a un entrenamiento intenso.
300 billones
El equipo encontró que el stock efectivo total de datos de texto públicos generados por humanos es del orden de 300 billones de tokens, con un intervalo de confianza del 90%. Esta estimación incluye solo datos que son de calidad suficientemente alta para ser utilizados para el entrenamiento y tiene en cuenta la posibilidad de entrenar modelos para múltiples épocas.
En principio, los datos generados por humanos son los que realmente interesan, ya que los datos sintéticos todavía no son fiables completamente y no son muy bien entendidos, de momento.
Por otra parte, los datos que no son públicos, como los textos de mensajería, no son utilizables totalmente por incurrir en ilegalidades de protección de datos. Además de estar muy sesgados, lo que no es bueno para los alineamientos de los modelos entrenados.
Y después, ¿qué?
La cuestión es que si hemos de seguir con este tipo de entrenamiento entonces necesitamos buscar datos donde sea. Por ejemplo, Google se plantea utilizar datos de sus servicios Google Docs. Otras empresas busca fuera del ámbito general gratuito, como Meta, que ha considerado comprar la editorial Simon & Schuster para tener acceso a todas sus obras literarias.
Datos sintéticos
Una de las alternativas es el uso de datos que se han generado por las propias IAs. Pero estos datos, actualmente, no son lo suficientemente buenos para el entrenamiento, tendremos que esperar a tener mejores modelos generadores... Para lo cual, necesitamos más datos.
La otra opción es reestructurar los algoritmos de IA para utilizar mejor y de manera más eficiente los datos de alta calidad existentes. Una estrategia que se está explorando se denomina aprendizaje curricular, que consiste en alimentar los modelos lingüísticos con datos en un orden específico con la esperanza de que la IA forme conexiones más inteligentes entre conceptos. Si funciona, el método podría reducir a la mitad los datos necesarios para ejecutar un modelo de IA.
Los costes de la IA
Si, a los esfuerzos de computación para el entrenamiento, añadieramos que los desarrolladores tengan que "comprar" datos, entonces puede que lleguemos a un encarecimiento de los modelos de nivel alto.
News Corp, uno de los mayores propietarios de contenidos de noticias del mundo (que tiene gran parte de su contenido de pago), dijo recientemente que estaba negociando acuerdos de contenido con desarrolladores de IA. Dichos acuerdos obligarían a las empresas de IA a pagar por los datos de entrenamiento, mientras que hasta ahora los han extraído de Internet en su mayoría de forma gratuita.
Veremos si encontramos una solución tecnológica en breve para no depender de tantos datos.
- Paper
https://arxiv.org - Estudio
https://epoch.ai - Crecimiento de los modelos
https://epoch.ai