
OpenAi o3, ¿tenemos una AGI?
Tiempo de lectura: 3 minutos
Cuando parece que estamos llegando al techo del desarrollo de los modelos de IA, OpenAI presenta o3, una nueva técnica que abre la puerta del avance en este campo con el modelo que supera las capacidades humanas.
Modelos de razonamiento
Cuando OpenAI presentó el model o1, se destacaba porque tardaba más tiempo en dar una respuesta. Esto es debido a que el modelo procesa la respuesta que genera para validarla y encontrar la que funciona mejor a la pregunta realizada.
Es decir, "reflexiona" a través de una cadena privada de pensamiento antes de responder. Cuando recibe una instrucción, hace una pausa, fragmenta la solicitud y la relaciona con otras indicaciones previas para entregar un resultado más preciso. Esta característica nos da la sensación aparente que el modelo "piensa" la respuesta, lo que le da un aire de inteligencia real.
Tal y como prometieron, OpenAi ha desarrollado una nueva versión de esta serie que está por encima de las puntuaciones del modelo o1 y, en tests complejos, puntúa por encima de la media humana. ¿Es esto la esperada AGI?
o3, nuestro último modelo de razonamiento, es un gran avance, con una mejora en la función escalonada en nuestros puntos de referencia más difíciles. Estamos comenzando las pruebas de seguridad y el red teaming ahora.
Greg Brockman
Evaluaciones
Una de las suites de evaluación más populares para la ingeniería de software es SWE-bench, un punto de referencia para evaluar las capacidades de los modelos de lenguaje grandes (LLM) en resolver problemas de software del mundo real provenientes de GitHub. El punto de referencia implica dat a los modelos un repositorio de código y una descripción del problema y desafiarlos a generar un código que resuelva el problema descrito.
Cada muestra en el conjunto de pruebas de SWE-bench se crea a partir de un problema de GitHub resuelto en uno de los 12 repositorios de Python de código abierto en GitHub. Cada muestra tiene una Pull Request (Propuesta de cambios) asociada, que incluye tanto el código de la solución como las pruebas unitarias para verificar la corrección del código.
Benchmarks
o3 mejora a o1 en 22,8 puntos porcentuales en SWE-Bench Verified. En este punto de referencia alcanza 71.7 puntos en frente a los 84.9 del modelo anterior.
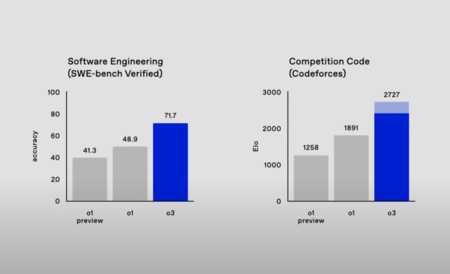
En Codeforces, competiciones de programación, o1 alcanza una puntuación de 1891 y o3 de 2727. Como decimos, estos modelos son útiles para muchas tareas complejas. Si nos enfocamos en puntos de referencia de matemáticas, en el American Invitational Mathematics Exam 2024, o1 registra una puntuación del 83.3%. o3, por su parte, presume de un 96.7%, fallando a una única pregunta.
Frontier Math
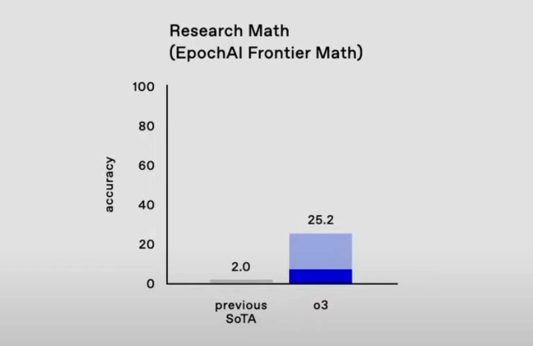
Frontier Math es uno de los nuevos benchmarks creados para poner a prueba los modelos y evitar la saturación de los benchmarks anteriores. El punto es que se trata de problemas matemáticos, no publicados antes en Internet, de dificultad extrema. Los matemáticos profesionales pueden tardar varios días en resolverlos.
Los modelos actuales pueden resolver un 2% de estos problemas. Bien, pues o3 llega a un 25.2% (!!!!)
ARC-AGI
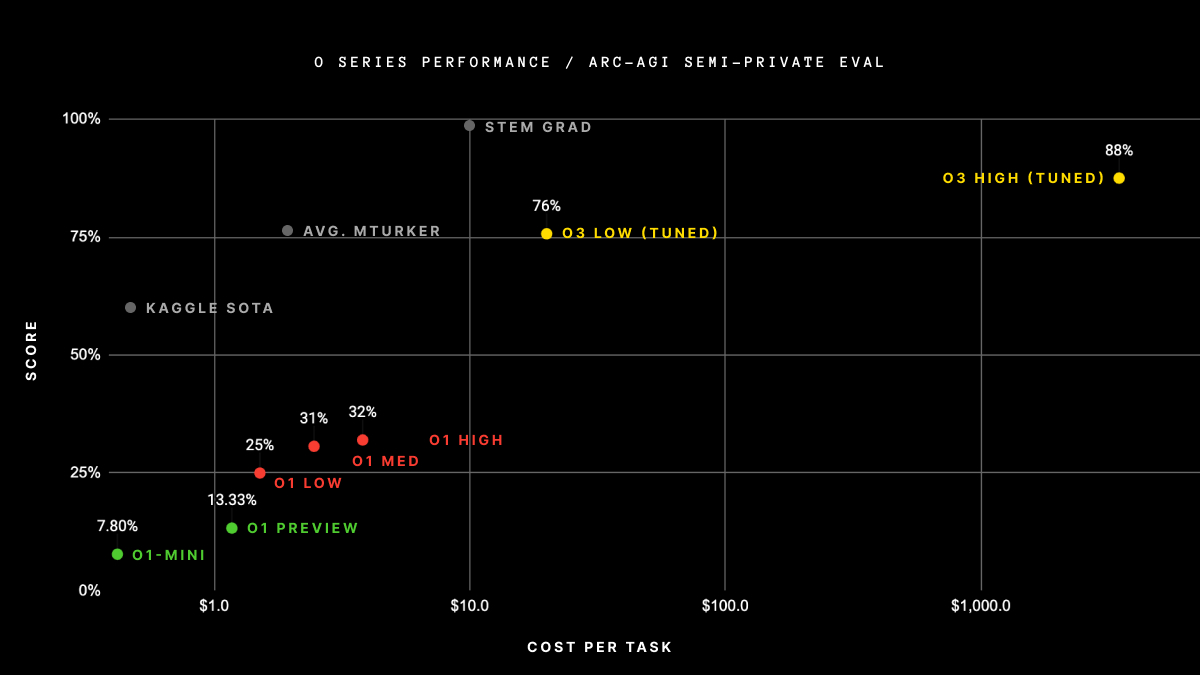
Este benchmark es el típico test de inteligencia que un humano pasa sin demasiada dificultad. Se trata de encontrar los patrones a partir de un ejemplo. Lo que se ha conseguido con el modelo o3 es superar la marca de la media humana que está en 85%. Con el modelo o3 de baja computación se llega al 75.7%, mientras que con el de alta computación, el que "piensa" más tiempo, llegamos al 87.5%.
Pero ese coste de computación significa un precio enorme, como se indica en la gráfica siguiente:
AGI
La Inteligencia Artificial General (AGI) se refiere a las IAs que puede realizar tareas de razonamiento y autoaprendizaje igual que lo hace un humano. O mejor que un humano.
François Chollet, una figura importante en el mundo de la IA y el creador de Keras, dice que “sabrás que la IA está aquí cuando el ejercicio de crear tareas que son fáciles para los humanos comunes pero difíciles para la IA se vuelva simplemente imposible”, es decir, cuando no podamos plantear problemas que no pueda resolver una AGI.
¿Estamos ante los albores de una AGI? Se ha dado un paso más para acercarnos a la super inteligencia, pero antes tendremos que revisar nuestras políticas de seguridad.
- WE-bench Verified
https://openai.com - ARC PRIZE
https://arcprize.org