
DeepSeek, el modelo chino
Tiempo de lectura: 4 minutos
Luo Fuli, con tan solo 29 años, ha logrado desarrollar un modelo de IA que no solo es más eficiente que las mejores creaciones de OpenAI, sino que además lo ha hecho con una fracción de los recursos.
DeepSeek
DeepSeek es el nombre de una empresa china que ha desarrollado un modelo de lenguaje llamado DeepSeek, como la empresa. DeepSeek es un modelo de código abierto, lo que no es raro ya que LlaMa 2, de Meta, también lo es y fue lanzado en 2023.
DeepSeek no es nuevo dentro del mercado de IAs, ya que desde 2024 salieron las primeras versiones, como DeepSeek V3, un modelo de larga escala LLM que supera a la mayoría de IA. En pruebas como la de programación, este modelo logró superar a Llama 3.1 405B, a GPT-4o y a Qwen 2.5 72B, aunque todos ellos tienen muchos menos parámetros y eso puede influir en el rendimiento y las comparaciones. Otro modelo es DeepSeek R1, razonador, que compite con ChatGPT o1.
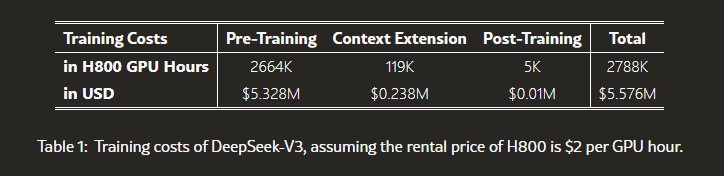
DeepSeek necesitó de 2,788 millones de horas de entrenamiento con un coste de 5,5 millones de dólares, las cifras se pueden ver en el documento técnico.
Código abierto
Que un modelo de lenguaje sea de código abierto, significa es que se puede ver cuál ha sido el proceso de entrenamiento, no que se pueda modificar el código para alterar los comportamientos de la IA, aunque se puede hacer un post-entrenamiento. Además, todos los modelos open source tienen alguna parte oculta que no se desvela. Y también es el caso de DeepSeek.
Que un modelo sea de código abierto, permite, entre otras cosas, que se pueda descargar completo y ejecutar de forma independiente en un ordenador local, sin necesidad de APIs o conexiones al los servidores de la empresa que lo ha creado, asegurando que no recogen datos del uso privado del modelo.
Ahora bien, esto no significa que no se necesite una potencia de cálculo enorme para que el modelo funcione de forma aceptable. Es decir, no basta descargarlo en un portátil y empezar a utilizarlo como si fuera ChatGPT de OpenAI. Aunque funcione, será tremendamente lento. Por eso se dispone de diferentes modelos especializados o de versiones destiladas.
¿Qué lo hace diferente?
Entre las característica de DeepSeek están el uso de 8 bits en vez de 32 bits, lo que reduce su volumen y equivalen a los destilados que se puede obtener de modelos como LlaMa y que, en cierta manera, disminuyen su precisión de respuesta.
Por otra parte parece que en vez de palabras, leen frases como tokens, lo que agiliza el proceso de aprendizaje. Y finalmente utiliza módulos especializados, lo que significa que no todos sus componentes funcionan de forma continuada, sino que solo se activan aquellos que tienen una función en cada momento, lo que genera un menor consumo de computación y, por lo tanto, energético.
En cuanto al hardware, DeekSeek ha utilizado unos 2.000 GPUs Nvidia H800, frente a los 16.000 GPUs H100 que utiliza OpenAI.
Además, el modelo viene bastante censurado por la ideología de China y no permite referencias políticas o temas que son sensibles.
El desplome de la bolsa
A la vista de un modelo de bajo coste de entrenamiento, muy bajo coste comparado con las cifras que manejan las grandes compañías del sector, de su uso público a gran escala, ya que es open source y gratuito, parece que los inversores no lo ven claro. La idea aparente es que los inversores cuestionan la necesidad de tanta inversión en infraestructura.
Todo apunta, a día de hoy, que se redimensionarán las inversiones en infraestructura para desarrollo de IAs. De todas formas, según el informe técnico, costó 5,576 millones de dólares; mucho menos de lo que se invierte en EE.UU.
¿Pero es esto así realmente?
La realidad
Lo primero de todo es que no tenemos garantías que lo hayan conseguido realmente con una tecnología novedosa. China tiene ya un historial de falacias. Pero, ¿es realmente una humillación a Estados Unidos? y, ¿los ingenieros de Silicon Valley no se han dado cuenta que se puede desarrollar una tecnología como la de DeepSeek?
Por otra parte, ¿es tan buena DeepSeek como IA de lenguaje? Recordemos que este modelo se caracteriza por haber sido entrenado a un coste muy barato, lo que implica que los precio de disponibilidad al gran público son muy bajos, pero esto no significa que realmente tenga las capacidades de los grandes modelos, como los de OpenAI.
Si revisamos os modelos LlaMa de meta, open source, veremos que no están a la altura de los modelos tipo ChatGPT, a menos que utilicemos los modelos como el LlaMa de 70 mil millones de parámetros, con el coste que representa.
La paradoja de Jevons
Todo esto nos lleva a que la realidad sea tener un empuje en el campo de la IA, proporcionando que la tecnología mejore la eficiencia en la producción de modelos, que serán más eficientes y aumentarán el uso de las IAs, es decir más demanda, por lo necesitaremos entrenar más modelos, más inteligentes.
La potencia de cálculo
Pero la cuestión que realmente manda es la potencia de cálculo. Aquellos que tengan la mayor capacidad de disponer de potencia de cálculo serán los que realmente tengan el poder dentro del sector.
Si DeepSeek realmente ha desarrollado un entrenamiento barato con la calidad de los modelos de Estados Unidos, lo que han conseguido es elevar el listón. Recordemos que los objetivos de las grandes compañías de IA son llegar a la AGI. Y para ello se están preparando con enormes instalaciones para procesar los futuros modelos.
La gran inversión anunciada por el presidente Trump pretende llegar a una AGI en un tiempo razonable. Pero si con la tecnología de entrenamiento de DeepSeek y su código abierto, se aplica a las grandes inversiones previstas, Estados Unidos puede llegar a la AGI en un tiempo menor. Y no solo eso, también puede sobrepasar los límites que se han establecido actualmente y llegar a donde nadie pensaba que se podía llegar.
- Colapso bursátil
https://cincodias.elpais.com - DeepSkeek
https://www.deepseek.com - Technical report
https://arxiv.org