
Web Scraping con Python y salida en CSV
Tiempo de lectura: 3 minutos
Tenemos la información que necesitamos en una página web, pero nos interesaria disponer de los datos en una hoja de cálculo donde los podamos examinar más fácilmente. Podemos recuperarlos.
Scrape
Tenemos la información que necesitamos en una página web, pero nos interesaria disponer de datos en una hoja de cálculo donde los podamos examinar más fácilmente y realizar nuestros cálculos en un formato de listado. El scraping es la técnica para extraer datos de sitios web.
Preparación
Vamos a utilizar la bibioteca BeautifulSoup para recuperar el DOM de una página web y poder navegar por él programáticamente. Lo que nos permitirá acceder y recuperar la información que nos interese.
En este ejemplo, la idea es recuperar en un CSV los nombres y descripción de los gestores de paquetes que se muestran en esta web de SourceForge, https://sourceforge.net/software/package-managers.
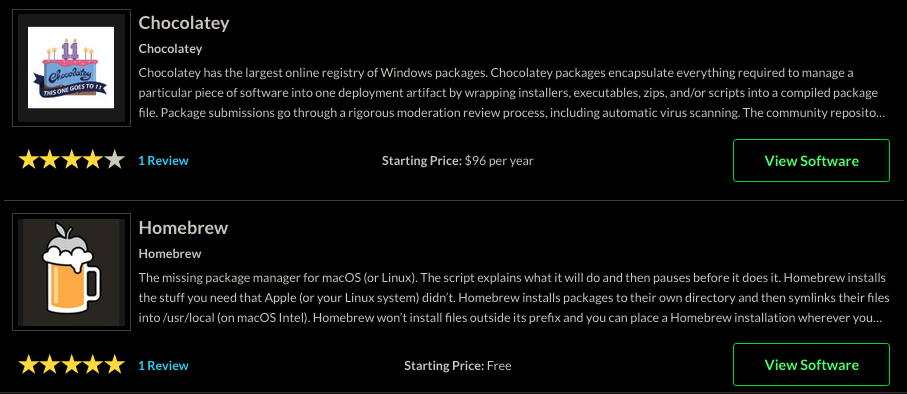
En la página de la que vamos a extraer la información, lo primero que necesitamos es identificar dónde se encuentra la información dentro del DOM de la página. para ello, utilizaremos las herramientas del navegador.
Primero nos posicionamos sobre el dato que nos intresa, botón derecho, aaprece un menú, seleccionamos Inspeccionar. Esto abre una ventana en la que se muestra el elemento HTML que contiene el dato.
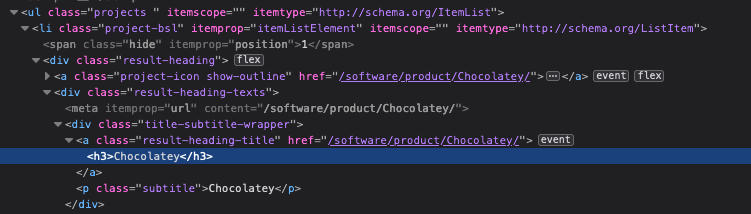
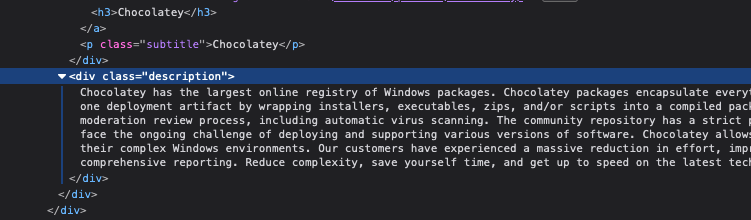
Repetimos el proceso con los datos que nos interesan para saber cómo identificar los elementos, de manera que le podamos indicar a BeautifulSoup lo que nos interesa. De la misma forma, nos fijaremos en los contenedores de la información, elementos DIV, por ejemplo, para que los tengamos agrupados con los datos relacionados.
El código
Pasemos a escribir el scraper. En un nuevo archivo scraper.py incluimos BeautifulSoup
from bs4 import BeautifoulSoup
import requests También necesitamos recuperar la página web que vamos a escanerar, por lo que incluiremos Requests y la descargaremos:
url = "https://sourceforge.net/software/package
-managers"
page = request.get(url)
En la variable page vamos a tener la respuesta del servidor con un código de estado, si todo es correcto, el código
A continuación creamos un objeto de BeautifulSoup para obtener el contenido de la página descargada:
soup = BeautifulSoup(page.content, 'html.parser')
y le hemos indicado que utilice un parse de HTML
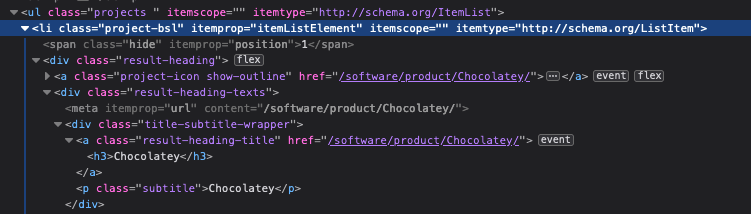
Ahora vamos a buscar los datos que nos interesan. Tenemos que hay un elemento <li> como contenedor, dentro del cual hay un <h3> y un <div> por lo tanto, creamos una lista e indicamos a bs4 que busque todos los elementos <li>
lists = soup.find_all('li', class_="project-bsl")
Observa que el parámetro class_ lleva un guión para diferenciar de la class de Python.
Ahora vamos a iterar en la lista para obtener cada uno de los datos que queremos. Primero, con un find en list, cada uno de los elementos de lists, el encabezado <h3>, del cual devolvemos el texto y a continuación el div que contiene el texto descriptivo.
for list in lists:
name = list.find('h3').text
description = list.find('div',
class_="description").text
print(name, description)
Ejecución
Ejecutamos
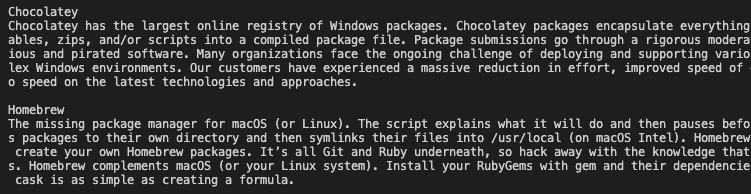
Salida a CSV
Solo nos queda enviar estos datos a la salida de un fichero de tipo CSV. Añadimos un import:
from csv import writer
Abrimos el fichero de salida y grabamos la línea de cabecera
with open('output.csv', 'w',
encoding='utf8', newline='') as f:
aWriter = writer(f)
header = ['Nombre','Descripción']
aWriter.writerow(header)
y, a continuación, adaptamos el código para que escriba en el fichero
for list in lists:
name = list.find('h3').text
description = list.find('div',
class_="description").text.replace('\n','')
info = [name, description]
aWriter.writerow(info) Ejecutamos y ya tenemos nuestro CSV con la información de la web

Código completo
El programa python completo es el siguiente
from bs4 import BeautifulSoup
import requests
from csv import writer
url = "https://sourceforge.net/software/package
-managers"
page = requests.get(url)
soup = BeautifulSoup(page.content, 'html.parser')
lists = soup.find_all ('li', class_="project-bsl")
with open('output.csv', 'w',
encoding='utf8', newline='') as f:
aWriter = writer(f)
header = ['Nombre','Descripción']
aWriter.writerow(header)
for list in lists:
name = list.find('h3').text
description = list.find('div',
class_="description").text.replace('\n','')
info = [name, description]
aWriter.writerow(info) - HTTP response status codes
https://developer.mozilla.org - Beautiful Soup docs
https://diaridigital.net